Stop Calling LLM APIs From Every Service — Use a Local AI Gateway Instead
Every team is re-implementing retry logic, API key management, and prompt logging. Here's why a local AI gateway pattern using OpenClaw solves this problem — with real code examples and architectural guidance.
Backend engineers, platform teams, and technical architects who are integrating LLMs into production systems and starting to feel the friction of doing it across multiple services independently.
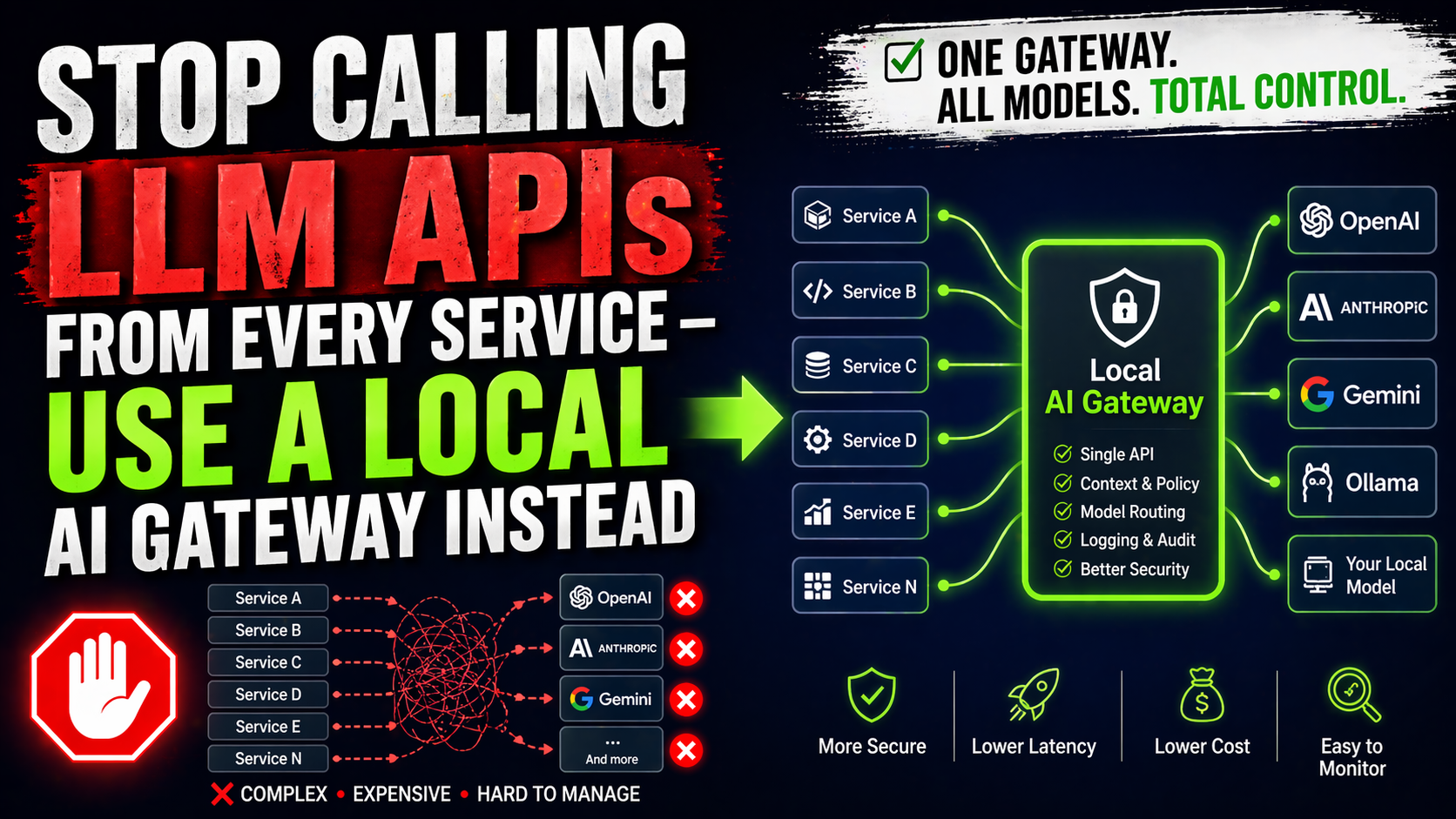
Your Architecture Probably Has an "LLM" Box Connected to Every Service — And It Is Becoming a Mess
Think about how this happened in your codebase. Service A needed summarization, so someone added an OpenAI client. Service B needed classification, so someone added the same client with slightly different configuration. Service C needed a different model entirely, so there is now a third implementation with its own retry logic, its own error handling, and its own approach to logging.
A year later, you have a dozen services that all talk to LLM APIs, none of them consistently, and no one has a clear picture of what is being sent where, how much it costs, or what happens when a model provider has an outage.
You have seen this pattern before. It is exactly what happened with authentication before OAuth. With caching before Redis. With message queues before Kafka. Every team rolled their own solution, the inconsistency accumulated, and eventually the industry converged on a standard pattern that centralized the concern and gave everyone a better foundation to build on.
AI infrastructure is in its pre-convergence phase right now. The teams that recognize this early and implement the right architectural pattern will spend the next few years building on a clean foundation. The teams that keep adding LLM clients to individual services will spend it paying down technical debt.
The Specific Problem: What Every Team Is Re-Implementing
When each service manages its own LLM integration, the duplication is not just annoying — it is structurally harmful. Here is what gets re-implemented, poorly, across every service that calls an LLM API independently:
Retry and timeout logic. Model APIs fail. They rate-limit. They return partial responses. Handling this gracefully requires exponential backoff, timeout configuration, and fallback behavior. Every service that does this independently will implement it slightly differently, and the differences will surface as inconsistent behavior that is difficult to debug across service boundaries.
API key management. Rotating credentials across services that each hold their own copy of an API key is operationally painful and security-risky. A leaked key in one service compromises everything — and the sprawl of key copies across services makes rotation a significant operational event rather than a routine procedure.
Prompt logging and observability. Understanding what your system is sending to LLMs, what it receives back, how long requests take, and how much they cost requires consistent instrumentation. When each service handles this independently, you end up with fragmented observability that makes it nearly impossible to reason about system-wide AI behavior or costs.
Context gathering. Most meaningful LLM interactions require context — user history, relevant data from other services, system state. Gathering this context in each service independently creates duplication and consistency problems, and makes it difficult to implement context management strategies that work well across the system.
The solution is not to write this shared logic as a library that each service imports. Libraries still run in-process and still require each service to manage connections, credentials, and configuration. The solution is to treat AI access as infrastructure — the same way you treat database access or message queue access — and put it behind a dedicated layer.
The Pattern: AI as a Local Gateway
The pattern is straightforward to describe: instead of each service maintaining its own LLM client and credentials, all services communicate with a local AI daemon that runs on the same machine or within the same network boundary. The daemon manages all provider connections, handles retry logic and failover, maintains audit logs, enforces policies, and provides a consistent interface that applications consume without needing to understand the underlying complexity.
Your services stop looking like this:
Service A → OpenAI API (its own client, its own key, its own retry logic)
Service B → Anthropic API (its own client, its own key, its own logging)
Service C → OpenAI API (duplicate of Service A, slightly different config)
Service D → Local model (totally different integration pattern)And start looking like this:
Service A → Local AI Gateway → OpenAI API
Service B → Local AI Gateway → Anthropic API
Service C → Local AI Gateway → OpenAI API
Service D → Local AI Gateway → Local model
All services: same interface, centralized credentials,
consistent logging, unified policy enforcementThe gateway becomes the single point of control for all AI interactions. Change the model provider — update the gateway configuration, not every service. Rotate API keys — update them in one place. Add logging — implement it once. Enforce a policy that sensitive data should only go to a local model — configure it centrally.
OpenClaw: A Concrete Implementation of This Pattern
OpenClaw is a local AI agent and gateway system that implements this architectural pattern. It is useful to understand it as three components working together: a local daemon that handles AI requests, an API layer that your applications communicate with, and a skills system that provides modular, reusable AI-powered capabilities.
Think of it as an API gateway combined with a sidecar proxy combined with a rules engine — but specifically designed for AI infrastructure rather than general-purpose API management.
Installation
On macOS and Linux:
curl -fsSL https://openclaw.ai/install.sh | bashOn Windows (PowerShell):
iwr -useb https://openclaw.ai/install.ps1 | iexVia npm (if you prefer package manager installation):
npm i -g openclaw@latestAfter installation, set up the daemon and verify it is running:
# Initialize and install the background daemon
openclaw onboard --install-daemon
# Verify the gateway is running
openclaw gateway status
# Open the local dashboard
openclaw dashboardThe gateway runs at localhost:18789 by default. Your services communicate with this local endpoint rather than directly with external model providers.
The Mental Model: A Sidecar for AI
If you are familiar with the sidecar pattern from service mesh architectures, OpenClaw occupies a comparable role for AI interactions. It runs alongside your application processes, intercepts and manages AI calls, provides observability, and enforces policies — without requiring your application code to understand or implement any of that complexity.
The mapping between OpenClaw concepts and backend infrastructure concepts you already know:
OpenClaw Skills → Microservices (modular, composable units of capability)
OpenClaw Channels → Transport (how requests flow between components)
OpenClaw Gateway → Load Balancer (routes requests to appropriate models/providers)
OpenClaw Policies → Middleware (rules applied to all requests passing through)A Real-World Configuration Example
Here is what a practical production configuration looks like — a setup where you have a hosted model for general tasks and a local model for anything involving sensitive data, with different channels for different interaction types and explicit policies governing what the gateway will and will not do:
# models.yaml
models:
general:
provider: anthropic
model: claude-sonnet-4-20250514
use_for: [summarization, drafting, general_queries]
sensitive:
provider: ollama
model: llama4:8b
use_for: [customer_data, financial_records, internal_docs]
# channels.yaml
channels:
- type: cli
name: developer_terminal
- type: slack
name: team_notifications
workspace: your-workspace
# policies.yaml
policies:
- name: no_autonomous_actions
rule: all_outputs_are_drafts
enforce: true
- name: sensitive_data_local
rule: if_context_contains_pii_use_sensitive_model
enforce: true
- name: audit_everything
rule: log_all_requests_and_responses
enforce: trueNotice what this configuration makes possible: your services make requests to the local gateway without specifying which model or provider to use. The gateway applies your policies — routing PII-containing requests to the local model, routing general requests to the cloud provider — without any of that logic living in your application services.
Audit Logging: Know What Your System Is Doing
One of the most practically valuable features of centralizing AI calls through a gateway is that you get comprehensive audit logging without implementing it in every service separately. OpenClaw writes all interactions to a structured log file:
~/.openclaw/audit.logEach log entry includes the requesting service, the model used, the request timestamp, the response latency, the token count (for cost tracking), and a hash of the request content. This gives you the ability to:
- Track AI costs by service and by model across your entire system
- Debug unexpected model behavior by examining exact inputs and outputs
- Audit compliance requirements around what data was sent where
- Identify performance bottlenecks in AI-dependent workflows
- Detect unusual usage patterns that might indicate misuse or errors
This kind of observability is genuinely difficult to achieve when AI calls are scattered across services. Through a central gateway, it comes essentially for free.
Skills as Microservices: A Production Mindset for AI Capabilities
The skills system in OpenClaw deserves particular attention because it reflects a disciplined approach to AI capability development that many teams have not yet adopted.
A skill is a modular, self-contained AI capability with defined inputs, defined outputs, version control, and testable behavior. Instead of scattering prompt engineering and AI logic throughout your codebase, you package each AI capability as a skill with its own directory structure, specification, and tests.
A typical skill directory looks like this:
pr-review-prep/
├── SKILL.md # Specification: description, requirements, examples
├── scripts/
│ └── risk-scan.sh # Deterministic pre-processing logic
└── test/
├── fixtures/ # Sample inputs for testing
└── expected/ # Expected outputs for validationThe SKILL.md file defines the skill's contract:
---
name: pr-review-prep
description: "Prepare a comprehensive PR review checklist based on changed files"
version: 1.2.0
metadata:
openclaw:
requires:
bins: ["gh", "bash"]
inputs:
- pr_number: integer
- repo: string
outputs:
- checklist: markdown
- risk_flags: array
---
## Usage
This skill fetches the diff for a PR, runs deterministic
risk checks, then asks the model to generate a structured
review checklist based on what it finds.
## Testing
Run `openclaw skill test pr-review-prep` to validate
against fixtures in test/.This approach treats AI capabilities the way mature engineering organizations treat any production dependency: with explicit contracts, version management, and tests. The skill can be updated, deployed, and rolled back independently of the services that consume it.
A Critical Pattern: Keep Business Logic in Code, Not Prompts
One of the most common mistakes in AI integration is encoding business logic in prompt text rather than in actual code. This makes behavior unpredictable, untestable, and difficult to audit.
The correct pattern: use deterministic code for business logic, and use AI for what AI is actually good at — generating natural language explanations, summaries, and analysis of things that code has already identified.
Here is the risk-scan script from the pr-review-prep skill, demonstrating this principle:
#!/bin/bash
# scripts/risk-scan.sh
# This script makes deterministic decisions about what requires attention.
# The AI model will then EXPLAIN these findings, not make them.
FILES=$(gh pr view "$1" --json files -q '.files[].path')
# Deterministic check: did application config files change?
if grep -Eq '(^|/)application(-[a-zA-Z0-9]+)?\.ya?ml$' <<< "$FILES"; then
echo "flag:config-change — review environment variable overrides"
fi
# Deterministic check: did database migrations change?
if grep -Eq '(^|/)db/migrate/' <<< "$FILES"; then
echo "flag:db-migration — verify rollback plan exists"
fi
# Deterministic check: did authentication code change?
if grep -Eq '(^|/)(auth|authentication|oauth)' <<< "$FILES"; then
echo "flag:auth-change — requires security review"
fi
# Deterministic check: did tests decrease relative to code?
CODE_LINES=$(git diff origin/main..HEAD -- '*.rb' | grep '^+' | wc -l)
TEST_LINES=$(git diff origin/main..HEAD -- '*_spec.rb' | grep '^+' | wc -l)
if [ "$TEST_LINES" -lt $((CODE_LINES / 3)) ]; then
echo "flag:insufficient-test-coverage — consider adding tests"
fiThe script produces a structured list of flags based on deterministic conditions. The AI model then takes this flag list and generates a human-readable review checklist that explains each flag, provides context, and suggests what reviewers should look for. The model is doing what models are good at — generating clear, contextual natural language. The decisions about what constitutes a risk are made in auditable, testable bash code.
Benefits Over the Distributed Approach
- No more duplicate retry and timeout logic — implemented once in the gateway, consistent everywhere
- Credential management in one place — rotate API keys without touching service code
- Model switching without service changes — update the gateway configuration to change which model a service uses
- Unified cost tracking — see exactly what you are spending on AI across your entire system
- Policy enforcement — routing rules, data sensitivity policies, and action restrictions enforced consistently
- Composable skills — reuse AI capabilities across services without duplicating prompt engineering
Honest Challenges
The gateway pattern is the right architectural direction, but it is worth being clear about where the current tooling is still maturing:
Skill authoring tooling is still evolving. The developer experience for creating, testing, and deploying skills is improving rapidly but is not yet as polished as the tooling for, say, writing and deploying microservices. Expect to invest time in this area and expect the tooling to get significantly better over the next year.
Observability tooling is limited. Compared to the rich ecosystem of observability tools for traditional infrastructure, AI-specific observability — understanding model behavior, prompt effectiveness, and output quality at scale — is still underdeveloped. The audit logs exist; the tooling to analyze them effectively is lagging.
Model differences can break workflows. Skills written against one model's behavior may not work identically with another. Prompt engineering that works well with Claude may behave differently with GPT or a local model. When you switch models through the gateway, you need to test your skills against the new model before deploying to production.
Engineering Best Practices for AI Infrastructure
Treat AI models as external dependencies — with all the engineering discipline that implies. Version the model you are using. Document behavioral expectations. Write tests. Plan for the model being unavailable or rate-limited.
Add policies before you need them. The right time to implement data routing policies and action restrictions is before you have a sensitive data incident, not after. The gateway pattern makes this easy — add the policies to your gateway configuration before the services that will be constrained by them are in production.
Log everything, from the start. AI costs and behaviors can be surprising. You want audit data from day one, not from the day you first notice an unexpected behavior or an unexpectedly large invoice.
Write tests for skills the same way you write tests for services. Define expected inputs and outputs. Use fixtures. Run the tests as part of your CI pipeline. A skill that has not been tested is a skill that will produce unexpected behavior in production.
The Larger Architectural Shift
The pattern described here is part of a broader shift that happens repeatedly in backend engineering when a new kind of infrastructure dependency becomes widespread. Consider the historical pattern:
Authentication: Every service rolls its own → OAuth / identity providers centralize it
Caching: Every service rolls its own → Redis / Memcached centralize it
Message queues: Every service rolls its own → Kafka / RabbitMQ centralize it
Service mesh: Every service rolls its own → Envoy / Istio centralize it
AI access: Every service is rolling its own → Gateway pattern will centralize itThe cycle is consistent: distributed implementation causes pain, the industry develops a centralized pattern, tooling matures around that pattern, and the centralized approach becomes the default. We are in the early stages of this cycle for AI infrastructure. The teams building the right foundation now will have a significant advantage over those who recognize the pattern only after the technical debt has accumulated.
Where to Start
Do not try to migrate your entire AI integration surface area to the gateway pattern at once. Pick one service, identify the LLM call that is causing the most operational friction, and build a skill for it. Get the audit logging working. Verify the policy enforcement. Then expand to a second service. The pattern's benefits compound as more of your system moves through the central gateway — but they start with the very first migration, making the incremental approach both lower risk and immediately rewarding.
# Step 1: Install and start the gateway
curl -fsSL https://openclaw.ai/install.sh | bash
openclaw onboard --install-daemon
# Step 2: Verify it is running
openclaw gateway status
# Step 3: Build your first skill
mkdir my-first-skill && cd my-first-skill
# Create SKILL.md with your capability specification
# Write your deterministic pre-processing scripts
# Add test fixtures
# Step 4: Replace one service's direct LLM call with a gateway call
# Update that service to call localhost:18789 instead of the model API directly
# Step 5: Check the audit log to confirm everything is flowing through
tail -f ~/.openclaw/audit.log